 With almost 25,000 LinkedIn impressions of our Facts from the Field series so far, I am excited to keep the momentum going and to share one of my favorite facts from this past October.
With almost 25,000 LinkedIn impressions of our Facts from the Field series so far, I am excited to keep the momentum going and to share one of my favorite facts from this past October.
At AppEnsure, it’s customary to fill out a Trip Report upon return from all business travel. The report summarizes the purpose, findings and recommendations to document business meetings and, in essence, justify the trip’s expense. Travelling from California to Georgia along with two engineers, I was off to meet with our newest customer, the VP of IT Architecture at a company that employs over 50,000 people. The purpose was to expand their deployment by 200%. Upon arrival, the VP met us in the lobby with two of his engineers and said, “I really hope I didn’t make the three of you come all the way here for nothing,” he shared after some friendly handshakes. I visualized a blank trip report in my head.
“The port isn’t open. I asked. I double-checked. But the port we need it isn’t open right now.” Days ago in preparation for today’s meeting, we discussed the technical needs to expand the deployment. He then quickly added, “But, the good news is that it’s lunch time and the port should be open by the time we finish eating. Then let’s dive into finding the answer to my latest problem. One that I haven’t even shared with y’all.”
Over our lunch, the team and I learned a lot about this VP’s twelve years at his company…and more about why they purchased AppEnsure. “The reason I bought your product was because it improved our visibility into XenDesktop performance,” he stated. “Now I have another application challenge and I think AppEnsure can help.” Their custom-built application – a revenue-generating, truly business-critical, heads-will-roll-if-this-goes-down application – was not performing as expected and the finger pointing game was in full effect for the last 36 hours. The application was a “modernized” legacy application that I’ll code name “Goliath” because it was massive (and, maybe, a reminder that even small things can bring a giant application down.)
“The latest release of Goliath went into production two days ago and I feel like the Applications group basically said ‘We built and tested the best application possible. The ball’s in your court, IT Ops, so make it perform with your infrastructure,’” he expressed with frustration. “But the problem as I see it is that 30% of application development is backlogged…multiple app dev projects are being outsourced to multiple vendors all happening simultaneously…and this ultimately results in constant change to the application architectures that Ops is just unaware of.” Adding to his frustration he talked about the App teams bringing in code instrumentation, but still not solving the problem and continuing to point the finger at the infrastructure. “It perfects the code but not the code’s interaction with the infrastructure. That’s why we are going to see what AppEnsure shows us today,” he said much more optimistically.
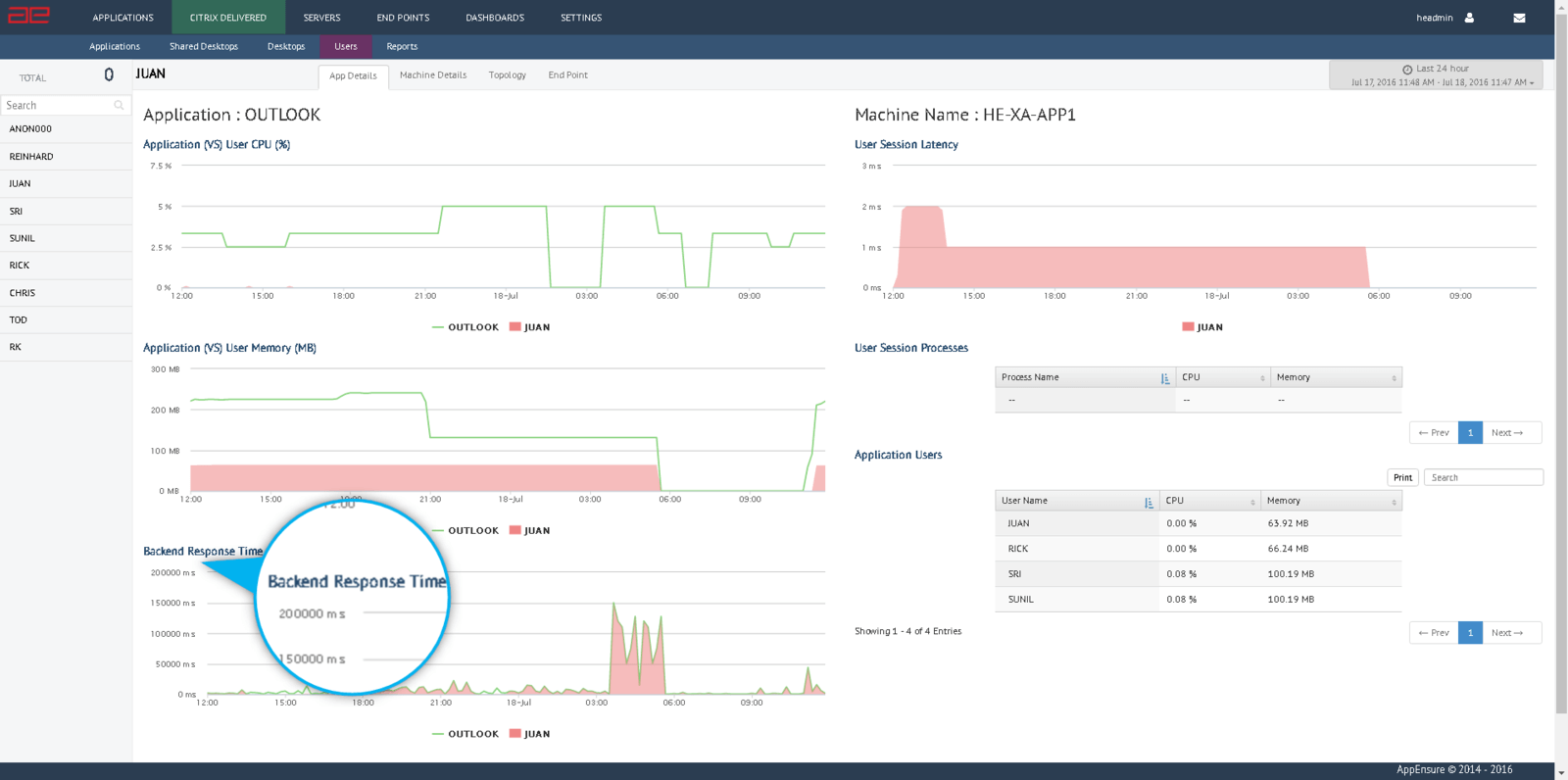
With a lunch long over and the deployment expanded to approximately 200 servers and 8000 desktops, it was now time to point fingers at AppEnsure to find the problem. With agents strategically deployed on the servers and desktops that serve and deliver Goliath, the application was automatically detected along with all of its dependents and critical information such as response time and throughput. But it wasn’t until we looked at the Topology Map for Goliath to produce three Texas-sized grins on these Georgians. “This is the view,” he said. “Because it’s real-time, it’s the only true view of how the application is working with the infrastructure. We can see changes that are taking place with workloads.” And with that statement, the three Texas-size grins were now coming from the visiting Californians.
AppEnsure and our combined team of six had discovered transactions to a backend SQL server directly from a presentation tier component in the workload. According to their “approved” architecture, the components of the presentation tier MUST NOT communicate directly with the SQL server. It seemed odd and we were skeptical of our finding but it was clear: a discovery by inter enquiry across three outsourced developers revealed that someone as part of an application enhancement had broken the SQL rule. “This is exactly the type of example I was describing at lunch,” he said. “Operations was totally unaware of the fact….until now. I need to make a quick phone call.”
Back in the lobby, and leaving for the airport surprisingly ahead of time, we started saying our goodbyes. Having shared many jokes about my team needing enough information to fill our trip report throughout the afternoon, I loved the VP’s last words to us. “We’re going to expand our deployment yet again with you next month. You can put that in your report.”
===========================================
Related Facts from the Field
Facts from the Field #1: “It’s Where you Measure”
Facts from the Field #2: “I Love It when People Pick on Citrix.”
“The Wild Card – The Citrix End User”
 How many of us IT professionals have been in a meeting similar to this: The chairs of various departments throughout the company are sitting around a long table and are giving a monthly summary. IT presents that the applications, network and servers were some amount of 9’s available and may explain an outage. The meeting goes on and then one of the heads explains a failure to meet department goals by stating some application was ‘slow’. IT is asked about it but unfortunately can only present data upon number of tickets and general up time. The slow comment is then picked up another department and IT is left in the untenable position of defending its metrics and supposedly achieved goals while other departments are blaming IT for lack of productivity.
How many of us IT professionals have been in a meeting similar to this: The chairs of various departments throughout the company are sitting around a long table and are giving a monthly summary. IT presents that the applications, network and servers were some amount of 9’s available and may explain an outage. The meeting goes on and then one of the heads explains a failure to meet department goals by stating some application was ‘slow’. IT is asked about it but unfortunately can only present data upon number of tickets and general up time. The slow comment is then picked up another department and IT is left in the untenable position of defending its metrics and supposedly achieved goals while other departments are blaming IT for lack of productivity.  The real problem is one of communication of expectations. IT has data that supports availability but the customer is complaining of slowness. Slowness is a subjective term and for IT to resolve the difficulty different metrics and SLAs are needed. Fortunately, there is a perfectly good way to measure slowness – time. When we think of availability we need to understand we are actually speaking of capacity while the users are interested in throughput. By measuring transaction time (the amount of time it takes for the user to commit an action and receive the corresponding data from the program they are using) IT can state how fast an application is working in objective terms. SLAs can be established that some percentage of the transactions during a reporting period will be completed within a certain amount of time. This allows business decisions based upon performance and is a salve for the mysterious ‘slow’ comment.
The real problem is one of communication of expectations. IT has data that supports availability but the customer is complaining of slowness. Slowness is a subjective term and for IT to resolve the difficulty different metrics and SLAs are needed. Fortunately, there is a perfectly good way to measure slowness – time. When we think of availability we need to understand we are actually speaking of capacity while the users are interested in throughput. By measuring transaction time (the amount of time it takes for the user to commit an action and receive the corresponding data from the program they are using) IT can state how fast an application is working in objective terms. SLAs can be established that some percentage of the transactions during a reporting period will be completed within a certain amount of time. This allows business decisions based upon performance and is a salve for the mysterious ‘slow’ comment.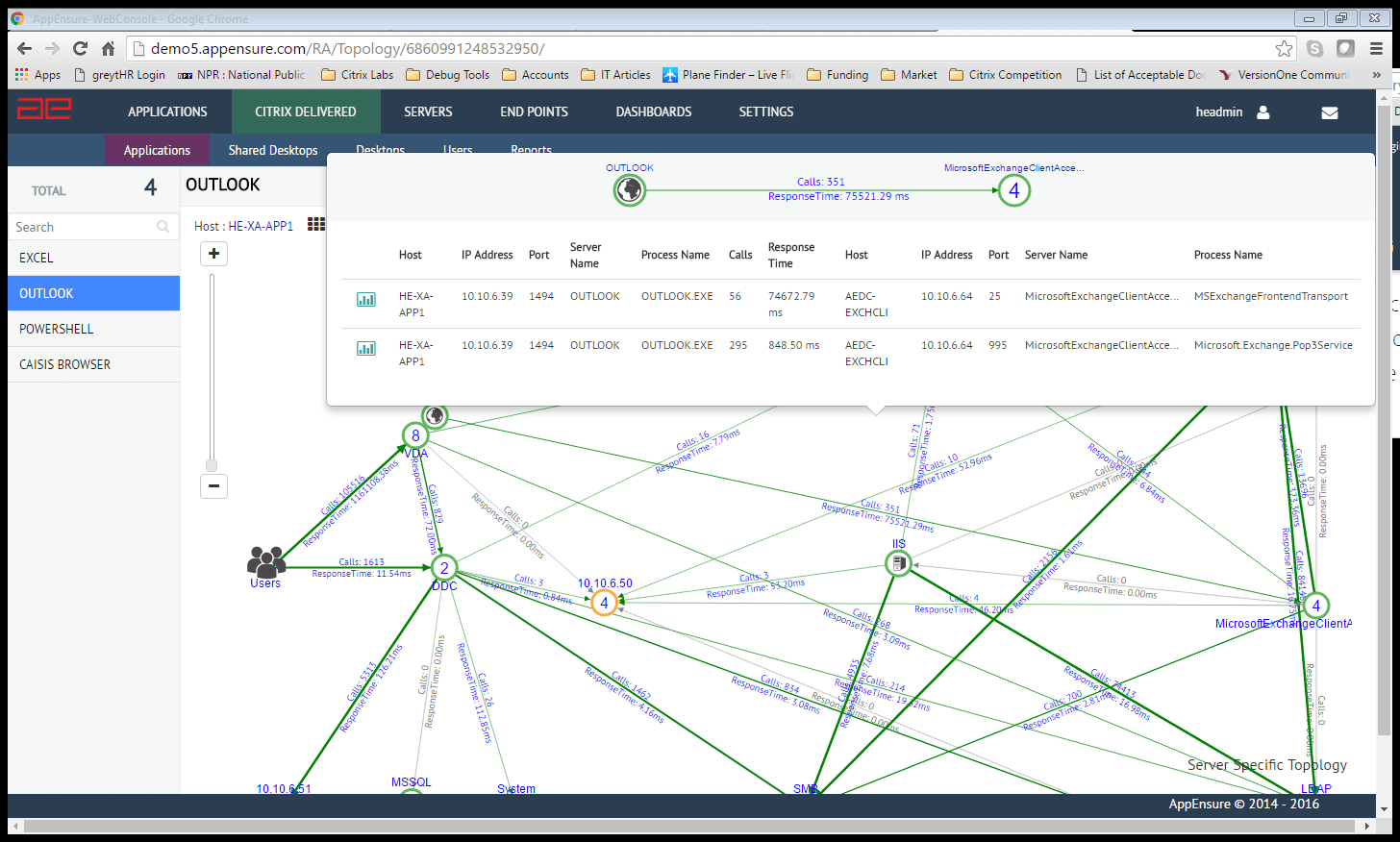
 IT has access to an amazing amount of data. Often we collect hundreds of data points on one server such as individual processor load, thread state, disk throughput both in and out etc. We then store this in a bin and use this to create a metric called something similar to server performance. When it comes time to provide reports (weekly, monthly and so on) IT then assign some poor person the job of collating this information. This is usually done by running a report and importing it into a spread sheet and then combining various servers and metrics into some grouping and calling it an application. Then some numbers are calculated and saved in the spreadsheet to create a performance over time graph. The same is done with database numbers, application performance, network statistics etc. This process is then repeated by levels of management combining more numbers into a single number to represent a service performance to allow reporting to more senior levels of management.
IT has access to an amazing amount of data. Often we collect hundreds of data points on one server such as individual processor load, thread state, disk throughput both in and out etc. We then store this in a bin and use this to create a metric called something similar to server performance. When it comes time to provide reports (weekly, monthly and so on) IT then assign some poor person the job of collating this information. This is usually done by running a report and importing it into a spread sheet and then combining various servers and metrics into some grouping and calling it an application. Then some numbers are calculated and saved in the spreadsheet to create a performance over time graph. The same is done with database numbers, application performance, network statistics etc. This process is then repeated by levels of management combining more numbers into a single number to represent a service performance to allow reporting to more senior levels of management. Given that IT is all about automating processes this has struck me as somewhat backwards. IT by and large is staffed by realists – the type that don’t respond well to marketing, want solutions and have little time for repetition. A second reality is that IT is a fledgling science. While it has a century under its’ belt it has not developed some niceties like the common taxonomy of biology; every company creates its own rankings and groupings of IT functions. Quite often a great deal of resources are used in creating the custom taxonomy. To add to the frustration of IT managers everywhere different off the shelf applications also present
Given that IT is all about automating processes this has struck me as somewhat backwards. IT by and large is staffed by realists – the type that don’t respond well to marketing, want solutions and have little time for repetition. A second reality is that IT is a fledgling science. While it has a century under its’ belt it has not developed some niceties like the common taxonomy of biology; every company creates its own rankings and groupings of IT functions. Quite often a great deal of resources are used in creating the custom taxonomy. To add to the frustration of IT managers everywhere different off the shelf applications also present